[対象: 上級]
Googleウェブマスターツールの「URLパラメータ」には「クロールしない」というオプションがあります。
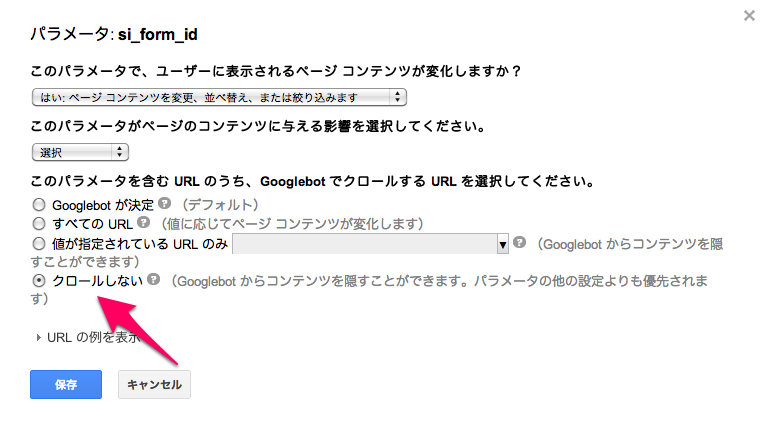
ところが「クロールしない」(英語表記では「NO URLs」)とはなっていますが、完全にクロールしないわけではなさそうです。
英語版の公式ヘルプフォーラムでGoogle社員のJohn Mueller(ジョン・ミューラー)氏が次のようにコメントしていました。
We see this setting as a strong hint, but it is not guaranteed to completely block crawling and indexing of those URLs.
この設定(「クロールしない」)を私たちは強いヒントとして見ていて、そのURLのクロールやインデックスを完全にブロックすることを保証したものではない。
robots.txtというよりはむしろnoindex robots meta タグに近い働きをするように思えます。
robots.txtはそのページの中身の取得を禁止しますが、noindex robots meta タグはクロール・インデックス自体は行われていて検索結果に表示させないだけですね。
この件に関して、John Mueller氏本人からGoogle+で次のようなコメントをもらえました。
Yes, this is just a signal, it’s not a strict directive. We may try to access the URLs regardless just to make sure that we’re not missing anything (eg the webmaster has used an incorrect setting), but it should crawl & index less that way. If you need to block crawling completely, you should use the robots.txt instead.
そのとおりで、これはただの合図であって厳格な命令ではない。何かを見逃していることがないように(たとえばウェブマスターが間違って設定する)、この設定にかかわらず対象のURLにアクセスしようとすることがあるかもしれない。ただしクロールとインデックス(の頻度)はそのように減少する。クロールを完全にブロックする必要があるならrobots.txtを代わりに使ったほうがいい。
rel=”canonical”と同じように“ヒント”として採用するだけで明らかに間違った使い方がされていそうなときは無視することがありえそうですね。
ただこの仕組みを逆手にとって、noindex robots meta タグのように検索結果には表示させないけれどクロール・インデックスはさせておいて、そのページにリンクがあった場合はリンク先ページにPageRankを渡すなんていうトリッキーな使い方も試せそうに思いました(良い子はやらなくていいですけど)。
今日は上級者向けの内容でした。
URLパラメータは重複コンテンツを防ぐために有用な機能です。
でも思わぬ落とし穴にはまることもありそうなので仕組みと動きを確実に理解したうえで設定しましょう。