[対象: 初級]
Googlebotがrobots.txtをチェックする頻度は基本的に1日1回で、記述されている内容には影響を受けません。
robots.txtをGooglebotがチェックする頻度に関して、GoogleのJohn Mueller(ジョン・ミューラー)氏が次のように公式ヘルプフォーラムでコメントしました。
robots.txtをだいたい1日に1回私たちはチェックする(1日2回以上の場合も時にはある)。
Disallowでクロールを完全にブロックしていたとしても、それが適用されるのは通常のクロールだけだ。たとえば、ウェブ検索のクロールに利用する。
言い換えれば、robots.txtで完全にブロックしていても、robots.txtが依然としてその状態のままかどうかを確かめるために定期的にチェックする。
robots.txtの取得は1日1回
Googleの場合、robots.txtを取得するのは通常1日1回です。
取得したrobots.txtをキャッシュとして保持します。
そのサイトのURLをクロールするたびに見に行くわけではありません。
この動きは以前にもブログで解説したとおりです。
ウェブマスターツールでは、robots.txtを更新したにも関わらず古い情報が表示されることがあります。
何かおかしいと思ったときは、「最終ダウンロード」の日付をチェックしてください。
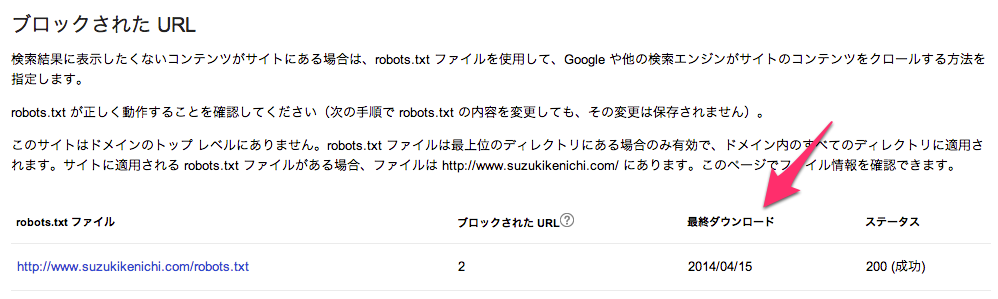
最終ダウンロードは、「◯時間前」と表示されることもあります。
なおrobots.txtのダウンロードに限らず、ウェブマスターツール内のレポートの日付は日本時間ではなく太平洋夏時間(PDT)です。(<=覚えておきましょう!)
サイト全体をブロックしていてもチェック頻度は変わらない
robots.txtでサイト全体のクロールをブロックしていたとしても、robots.txtのチェック頻度には影響を与えないとのことです。
つまり「1日に1回」は保たれます。
Mueller氏によるコメントは下の投稿に対してでした。
サイト全体をブロックしていたrobots.txtを編集して、Fetch as Googleですぐに更新しようとしたが取得に失敗した。
前に書いてあった拒否の記述を覚えていたためだと思われる。
サイト全体をブロックしているので、Fetch as Googleを使うとrobots.txtへのクロールまでブロックされてしまうのです。
しかし、robots.txtのチェックは通常のクロールとは別のプロセスなので、たとえ完全拒否していても定期的(1日1回)にチェックしにくるということをMueller氏は説明しました。
もっともサイト全体のブロックを解除した後、個々のURLにGooglebotがいつクロールするかはまた別の要因が絡んできます。
すぐにクロールされるわけではないことを僕から補足しておきます。
この記事のまとめです。
- 1日に1回、robots.txtをGooglebotはチェックする
- 通常のクロールとは異なりチェック頻度は記述内容に影響を受けない